Fully open multimodal large language models (MLLMs) currently lag behind proprietary counterparts, primarily due to a significant gap in data quality for supervised fine-tuning (SFT). Existing open-source datasets are often plagued by widespread noise and a critical deficit in complex reasoning data, such as Chain-of-Thought (CoT), which hinders the development of advanced model capabilities.
Addressing these challenges, our work makes three primary contributions. First, we introduce Honey-Data-15M, a new SFT dataset comprising approximately 15 million QA pairs, processed through multiple cleaning techniques and enhanced with a novel dual-level (short and long) CoT enrichment strategy. Second, we introduce HoneyPipe, the data curation pipeline, and its underlying framework DataStudio, providing the community with a transparent and adaptable methodology for data curation that moves beyond static dataset releases. Finally, to validate our dataset and pipeline, we train Bee-8B, an 8B model on Honey-Data-15M.
Experiments show that Bee-8B establishes a new state-of-the-art (SOTA) for fully open MLLMs, achieving performance that is competitive with, and in some cases surpasses, recent semi-open models such as InternVL3.5-8B. Our work delivers to the community a suite of foundational resources, including: the Honey-Data-15M corpus; the full-stack suite comprising HoneyPipe and DataStudio; training recipes; an evaluation harness; and the model weights. This effort demonstrates that a principled focus on data quality is a key pathway to developing fully open MLLMs that are highly competitive with their semi-open counterparts.
To address the challenges of data noise and the reasoning gap in open-source datasets, we developed HoneyPipe, an automated and reproducible workflow built on our DataStudio framework. It systematically transforms a vast, raw data pool into a high-quality, dual-level Chain-of-Thought (CoT) dataset suitable for supervised fine-tuning (SFT).
Figure 1: The HoneyPipe data curation pipeline with five key stages: data aggregation, noise filtering, short CoT enrichment, long CoT enrichment, and fidelity verification.
The pipeline consists of several key stages:
The primary output of our pipeline is Honey-Data-15M, a large-scale, multimodal SFT dataset with 15 million meticulously curated samples. It is designed to serve as a new cornerstone for the fully open MLLM community. A defining feature is its enrichment with dual-level CoT reasoning—approximately 12.2 million short CoT samples and 2.7 million long CoT samples—which provides tailored reasoning depth across a wide spectrum of critical domains like "General" visual understanding and "STEM" for symbolic reasoning.
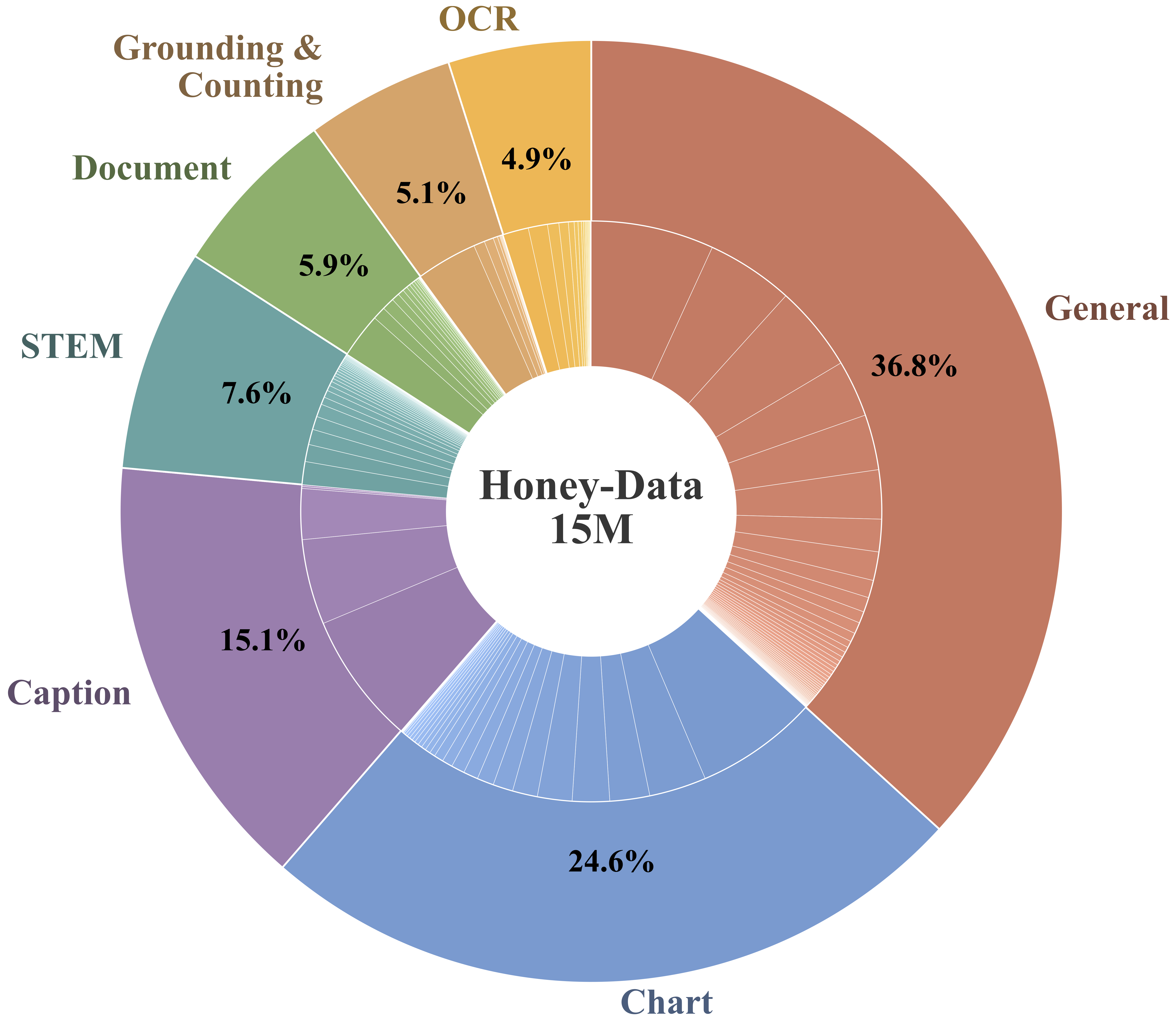
Figure 2: Category distribution of Honey-Data-15M dataset.

Figure 3: Data collection of Honey-Data-15M. A detailed breakdown of our dataset's composition across seven major categories. The number of samples (in thousands) is listed for each source. The * denotes that the data contains the long CoT response.
To validate our Honey-Data-15M, we trained Bee-8B, a new 8B parameter model, based on Qwen3-8B, on the full Honey-Data-15M dataset. Bee-8B establishes a new performance bar for fully open models, particularly in factual accuracy and complex reasoning, and proves highly competitive with recent semi-open models. These results confirm our core thesis: a focus on high-quality data curation is critical for creating models that can rival leading semi-open counterparts.
| Task | Benchmark | LLaVA OneVision-7B* |
Molmo -7B-D* |
Qwen2.5 -VL-7B† |
Keye-VL -8B† |
InternVL3.5 -8B† |
Bee-8B -SFT* |
Bee-8B -RL* |
|---|---|---|---|---|---|---|---|---|
|
General VQA |
AI2D | 81.4 | 81.0 | 84.3 | 86.7 | 84.0 | 83.8 | 85.3 |
| BLINKval | 48.2 | 49.7 | 56.4 | 52.0 | 59.5 | 52.5 | 55.0 | |
| CountBench | — | 84.8 | 74.1 | 78.0 | — | 90.5 | 93.0 | |
| HallusionBenchavg | 31.6 | 46.4 | 52.9 | 67.0 | 54.5 | 59.8 | 58.2 | |
| MMBench-CNdev | — | — | 81.3 | 92.0 | — | 81.2 | 84.2 | |
| MMBench-ENdev | 80.8 | — | 82.1 | 91.5 | — | 83.0 | 85.5 | |
| MMMUval | 48.8 | 45.3 | 58.6 | 71.4 | 73.4 | 66.8 | 66.1 | |
| MMMU-Prostandard | 29.5 | — | 34.7 | 47.1 | — | 50.4 | 50.7 | |
| MMStar | 61.7 | 56.1 | 63.9 | 75.5 | 69.3 | 69.0 | 71.4 | |
| MMT-Benchval | 59.3 | 56.3 | 63.6 | 65.9 | 66.7 | 64.6 | 67.0 | |
| MMVet | 57.5 | 41.5 | 67.1 | 79.0 | 83.1 | 83.3 | 83.9 | |
| MMVP | — | — | 73.3 | 79.0 | — | 80.7 | 82.0 | |
| POPEavg | 88.4 | 89.0 | 86.4 | 86.0 | 88.7 | 84.0 | 84.8 | |
| RealWorldQA | 66.3 | 70.7 | 68.5 | 67.7 | 67.5 | 70.1 | 73.1 | |
| VisuLogic | — | — | 20.0 | 25.6 | — | 24.4 | 26.5 | |
| VLMs are Blind | 39.2 | — | 37.4 | 57.1 | — | 55.8 | 56.5 | |
|
Table & Chart & OCR |
CharXivDQ | — | — | 73.9 | 77.7 | 72.2 | 84.7 | 84.8 |
| CharXivRQ | — | — | 42.5 | 45.4 | 44.4 | 55.3 | 57.3 | |
| ChartQAtest | 80.0 | 84.1 | 87.3 | 86.3 | 86.7 | 86.7 | 86.1 | |
| DocVQAval | — | — | 95.5 | 88.5 | — | 87.2 | 87.0 | |
| InfoVQAval | — | — | 81.4 | 67.4 | — | 72.3 | 72.9 | |
| OCRBench | 62.2 | 65.6 | 86.4 | 85.1 | 84.0 | 83.1 | 82.5 | |
| SEED-Bench2-Plus | 65.4 | 67.6 | 70.4 | 69.4 | 70.8 | 67.7 | 68.5 | |
|
Math & Reasoning |
DynaMathworst | 9.0 | — | 21.0 | 37.3 | 37.7 | 41.3 | 40.5 |
| LogicVista | 33.3 | — | 44.1 | 54.8 | 57.3 | 56.8 | 61.3 | |
| MathVersevision_only | 26.2 | 4.2 | 25.1 | 59.8 | 61.5 | 61.9 | 67.0 | |
| MathVision | 18.3 | 16.2 | 25.4 | 46.0 | 56.8 | 46.8 | 50.0 | |
| MathVistamini | 63.2 | 51.6 | 68.2 | 80.7 | 78.4 | 78.6 | 81.4 | |
| WeMath | 20.9 | — | 35.2 | 60.7 | 57.0 | 55.0 | 59.8 |
Table 1: Performance comparison of Bee-8B with other fully open (*) and semi-open (†) models across various benchmarks. The top and second-best scores for each benchmark are highlighted.
@article{zhang2025bee,
title={Bee: A High-Quality Corpus and Full-Stack Suite to Unlock Advanced Fully Open MLLMs},
author={Zhang, Yi and Ni, Bolin and Chen, Xin-Sheng and Zhang, Heng-Rui and Rao, Yongming and Peng, Houwen and Lu, Qinglin and Hu, Han and Guo, Meng-Hao and Hu, Shi-Min},
journal={arXiv preprint arXiv:2510.13795},
year={2025}
}